Cloud server CPU performance comparison
2019-12-12
Alternate titles: "The cloud makes no sense", "Intel Xeon processors are slow", "The Great vCPU Heist".
I recently decided to try to move some of my CPU-intensive workload from my desktop into the "cloud". After all, that's supposedly what those big, strong and fast cloud servers are for.
I found that choosing a cloud provider is not obvious at all, even if you only want to consider raw CPU speed. Operators do not post benchmarks, only vague claims about "fastest CPUs". So I decided to do my own benchmarking and compiled them into a very unscientific, and yet revealing comparison.
I was aiming for the fastest CPUs. Most of my needs are for interactive development and quick builds, in terms of wall clock performance. Which means CPU performance matters a lot. Luckily, that's what all cloud providers advertise, right?
I decided to write up my experiences because I wish I could have read about all this instead of doing the work myself. I hope this will be useful to other people.
Providers tested
In alphabetical order:
- Amazon AWS (c5.xlarge, c5.2xlarge, c5d.2xlarge, z1d.xlarge)
- Digital Ocean (c-8, c-16)
- IBM Softlayer (C1.8x8)
- Linode (dedicated 8GB 4vCPU, dedicated 16GB 8vCPU)
- Microsoft Azure (F4s v2, F8s v2)
- Vultr (404 4vCPU/16GB, 405 8vCPU/32GB)
Why those? Well, those are the ones I could quickly find and sign up for without too much hassle. Also, those are the ones that at least promise fast CPUs (for example, Google famously doesn't much care about individual CPU speed, so I didn't try their servers).
Setting up and differences between cloud providers
Signing up and trying to run the various virtual machines offered by cloud operators was very telling. In an ideal world, I would sign up on a web site, get an API key, put that into docker-machine and use docker-machine for everything else.
Sadly, this is only possible with a select few providers. I think every cloud operator should contribute their driver to docker-machine, and I don't understand why so few do. You can use Digital Ocean, AWS and Azure directly from within docker-machine. The other drivers are non-existent, flaky or limited, so one has to use vendor-specific tools. This is rather annoying, as one has to learn all the cute names that the particular vendor has invented. What do they call a computer, is it a server, plan, droplet, size, node, horse, beast, or a daemon from the underworld?
One thing I quickly discovered is that what the vendors advertise is often not available. As a new user, you get access to the basic VM types, and have to ask your vendor nicely so that they allow you to spend more money with them. This process can be quick and painless with smaller providers, but can also explode into a major time sink, like it does with Azure. There was a moment when I was spending more time dealing with various tiers of Microsoft support than testing. I find this to be rather silly and I don't understand why in the age of global cloud computing I still have to ask and specify which instances I'd like to use in which particular regions before Microsoft kindly allows me to.
Assuming you can actually get access to VM instances, there is a big difference in how complex the management is. With Digital Ocean, Vultr or Linode you will be up and running in no time, with simple web UIs that make sense. With AWS or Azure, you will be spending hours dealing with resources, resource groups, regions, availability sets, ACLs, network security groups, VPCs, storage accounts and other miscellanea. Some configurations will be inaccessible due to weird limitations and you will have no idea why. A huge waste of time.
The benchmark
I used the best benchmark I possibly could: my own use case. A build task that takes about two and a half minutes on my (slightly overclocked) i7-6700K machine at home. I started signing up at various cloud providers and running the task.
After several tries, I decided to split the benchmark into two: a sequential build and a parallel build. Technically, both builds are parallel and use multiple cores to a certain extent, but the one called "parallel" uses "make -j2" to really load up every core the machine has, so that all cores are busy nearly all of the time.
The build is dockerized for easy and consistent testing. It mounts a volume with the source code, where output artifacts go, too. It does require a fair bit of I/O to store the resulting files, but I wouldn't call it heavily I/O-intensive.
Methodology
A single test consisted of starting a cloud server, provisioning it with Docker (both were sometimes done automatically by docker-machine), copying my source code to the server, pulling all the necessary docker images, and performing a build.
The total wall clock time for the build was measured. The smaller the better. I always did one build to prime the caches and discarded the first result.
I tried to get six builds done, over the course of multiple days, to check if there is variance in the results. And yes, there is very significant variance, which was a surprise.
For some cloud providers (Linode and IBM) the build times were so abysmal that I decided to abandon the effort after just two builds. No point in torturing old rust.
I also threw in results for my own local build machine (a PC next to my desk), with no virtualization (but the build was still dockerized), and a dedicated EX62-NVMe server from Hetzner.
Results
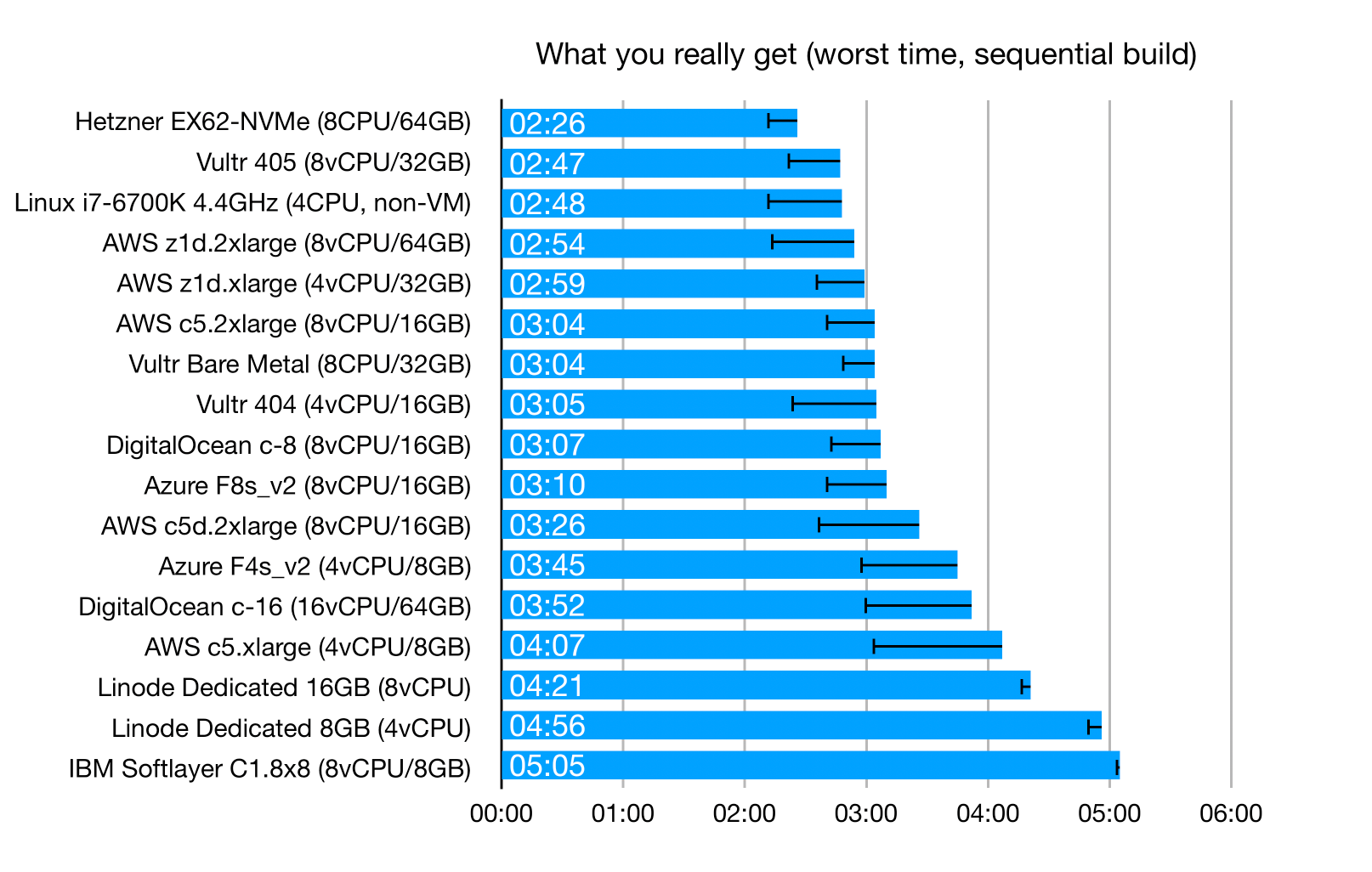
I first created rankings for average build times, but then realized that with so much variance, these averages make little sense. What I really care about is the worst build time, because with all the overbooking and over-provisioning going on, this is what I really get. I might get better times if I'm lucky, but I'm paying for the worst case.
The error bars indicate how much better the best case can be. As you can see, in some cases the differences are very significant.
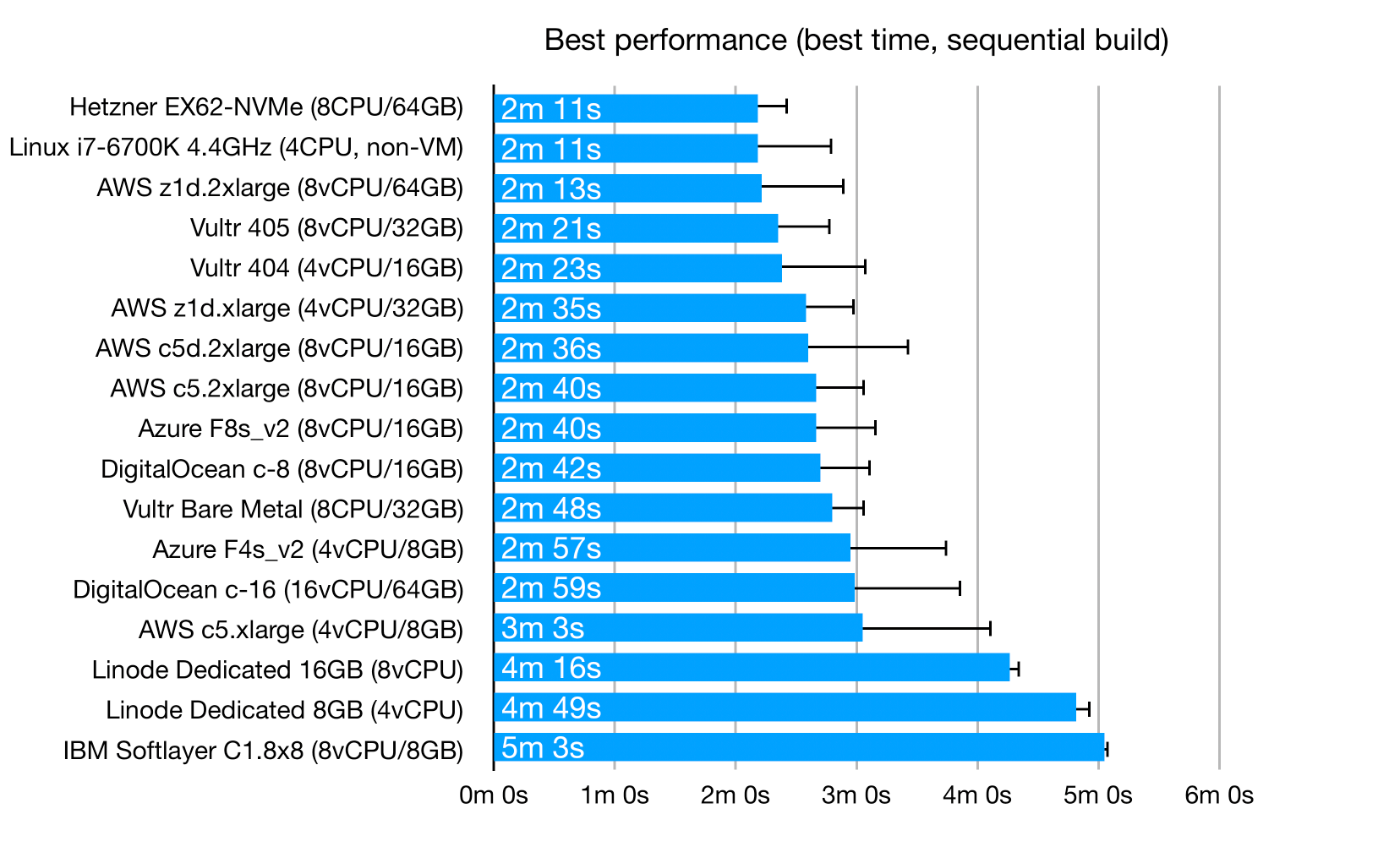
These are the worst-case results for "sequential" builds (see "The benchmark" above for a description of what "sequential" means):
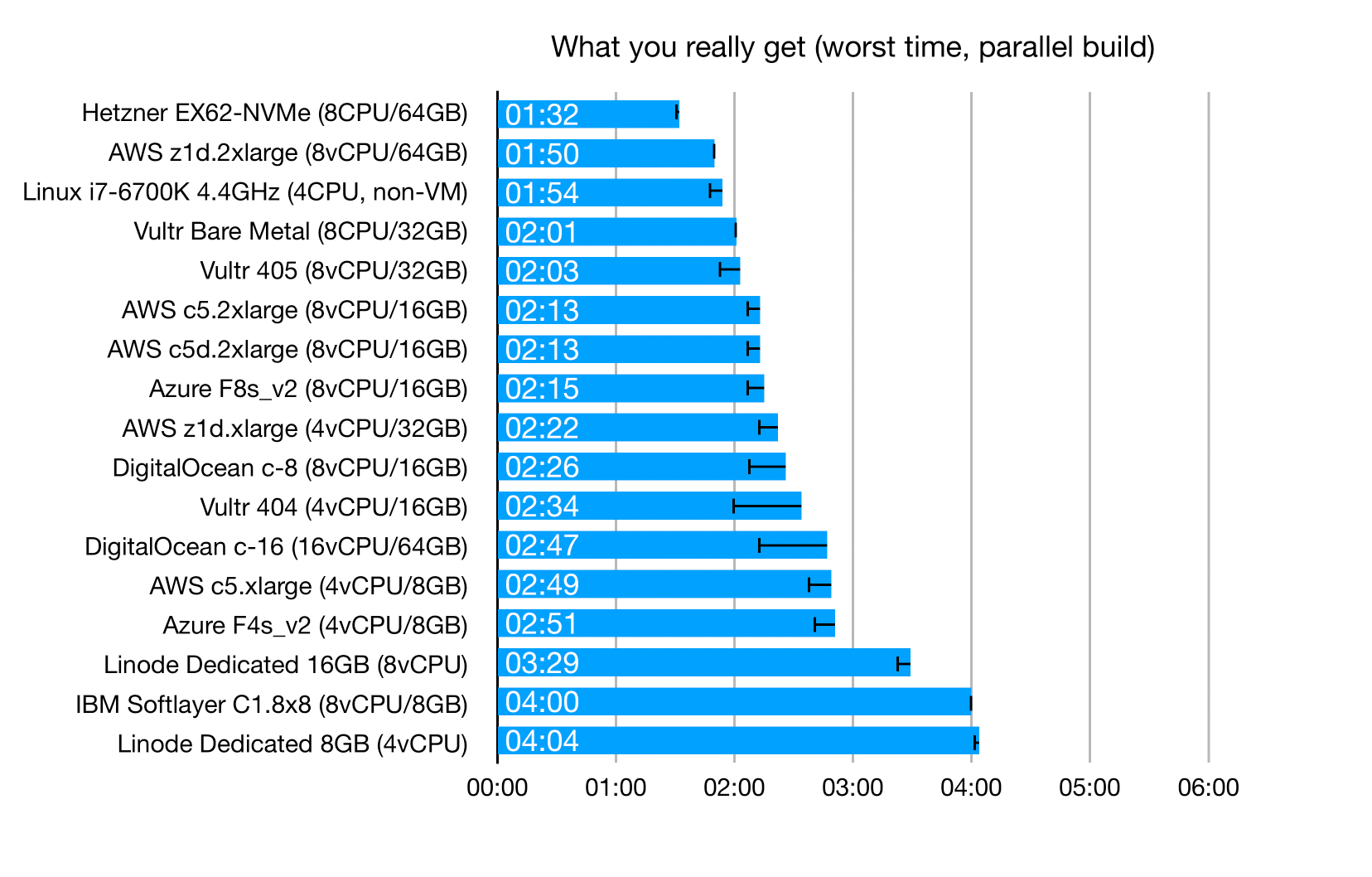
These are the worst-case results for "parallel" builds:
And this is the best case you can possibly get using a "sequential" build, if you are lucky:
The ugly vCPU story
What cloud providers sell is not CPUs. They invented the term "vCPU": you get a "virtual" CPU with no performance guarantees, while everybody still pretends this somehow corresponds to a real CPU. Names of physical chips are thrown around.
Those "vCPUs" correspond to hyperthreads. This is great for cloud providers, because it lets them sell 2x the number of actual CPU cores. It isn't so great for us. If you try hyperthreading on your machine, you will see that the benefits are on the order of 5-20%. Hyperthreading does not magically double your CPU performance.
If you wondered why everybody was so worried about hyperthreading-related vulnerabilities, it wasn't because of performance loss. It was because if we pressured the cloud providers, they would have to disable hyperthreading, and thus cut the number of "vCPUs" they are selling by a factor of two.
In other words, we now have a whole culture of overselling and overbooking in the cloud, and everybody accepts it as a given. Yes, this makes me angry.
Now, you might get lucky, and your VMs might have neighbors who do not use their "vCPUs" much. In that case, your machines will run at full (single-core) performance and your "vCPUs" will not be much different from actual CPU cores. But that is not guaranteed, and I found that most of the time you will actually get poor performance.
Intel® Xeon® processors are slow
There. I've said it. These processors are slow. Dog slow, in fact. We've been told over the years that the Intel® Xeon® chips are the powerhouses of computing, the performance champions, and cloud providers will often tell you which powerful Xeon® chips they are using. The model numbers are completely meaningless at this point, which I think is intentional confusion, so that even a 6-year old chip branded with the Xeon® name appears to be powerful.
Fact is, Xeon® processors are indeed very good, but for cloud providers. They let them pack lots of slow cores onto a single CPU die, put that into a server, and then sell twice that number of cores as "vCPUs" to us.
Now, if your workload is batch-oriented and embarassingly parallel, and if you can make 100% use of all the cores, then Xeon® processors might actually make sense. For other, more realistic workloads, they are completely smoked by desktop chips with lower core counts.
Of course, if this were the case, then everybody would buy desktop chips. Which is why Intel intentionally cripples those, removing ECC RAM support, thus making them more unreliable. And desktop chips are inconvenient for cloud providers, because you can't get as many "vCPUs" from a single physical server. Still, there are providers where you can get servers with desktop chips — Hetzner, for example, and these servers come out at the very top of my performance charts, being a fraction of the cost.
In other words, what we actually buy when we order our "Powerful compute-oriented Xeon®-powered VM" is a hyperthread on a dog-slow processor.
Enterprise shmenterprise
But, I can hear you say, this is wrong! Intel® Xeon® processors are for ENTERPRISE workloads! The serious stuff, the real deal, the corporate enterprisey synergistic large-mass cloud computing workloads that Real Enterprises use!
Well, my build is mostly Java execution and Java AOT compilation. Dockerized. That enterprisey enough? There is also some npm/grunt (it's a modern enterprise), with a bunch of I/O. It can make use of multiple cores, although not perfectly. I'd say it's the ideal "enterprise" use case.
Seriously, Xeon® chips are just plain slow. The benchmarks show it, especially in the single-threaded CPU performance part. They still rank relatively well in the multi-threaded benchmarks, but remember, a) your code is not embarassingly parallel most of the time, b) you will be renting 4-8 "vCPUs" (hyperthreads), not 16 actual cores that you're looking at in the GeekBench results.
Takeaways
If you want to spin up a relatively fast developer-friendly cloud server for software development, I'd say that Vultr and Digital Ocean are the top picks.
Digital Ocean is by far the most user- and developer-friendly. If you have little time, just go with them. Things are simple, make sense, and are fun to use. As an example, Digital Ocean lets you configure firewall rules and apply them to servers based on server tags. Any server deployed with a certain tag will then use those firewall rules. Simple, makes sense, quick and easy to use. Now go and try doing the same in Azure, let us know in a week how things are going.
Vultr has some rough edges, but is a very promising provider. Almost as user-friendly as Digital Ocean (but no docker-machine driver!). If you want to use attached storage, you will run into problems (attaching storage reboots the machine, which their support tells me is expected behavior).
You can get slightly faster machines at AWS if you pay a lot more. The z1d instances are advertised as fast. My testing shows them to be only slightly faster, which probably isn't worth the price increase over a c5.2xlarge.
Buying more "vCPUs" often gets you better performance, even for the sequential build case. This is a bit surprising, until you realize that you are buying hyperthreads on an over-provisioned machine. If you buy more hyperthreads, you push out the neighbors and "reserve" more of the real CPU cores for yourself.
The best performance comes from… desktop-class Intel processors. My old i7-i6700K is near the top of the charts, so is Hetzner's EX62-NVMe server with an i9-9900K. The EX62-NVMe is 64€/month, so for development it might make sense to just rent one or two and not bother with on-demand cloud servers at all.
Apart from Hetzner's desktop CPU offerings, there seems to be no way to get a cloud server with fast single-core performance.
Another conclusion from these benchmarks is that I decided to buy an iMac for my development machine, not an iMac Pro. Sure, I would like to have the improved thermal handling of the iMac Pro, as well as better I/O, but I do not want the dog-slow Xeon® processor. Perhaps it makes sense if you load all cores with video encoding/processing, but for interactive development it most definitely does not, and a desktop-class Intel CPU is a much better fit.